Why pages are not indexed: understand the process and fix issues more efficiently
This guide explains the basics of indexing, the Discover, Crawl, and Index phases, common problems in each phase, and practical ways to investigate and improve them.
The basics of indexing
Indexing is the process by which a search engine discovers a web page, understands it, and stores it in a form that can later appear in search results. If a page is not indexed, it is effectively invisible from an SEO perspective.
Crawlers and websites
Search engine crawlers such as Googlebot revisit pages regularly to detect new content and changes. The structure of the website, its internal links, and settings such as robots.txt all influence how efficiently this happens.
The search interaction model
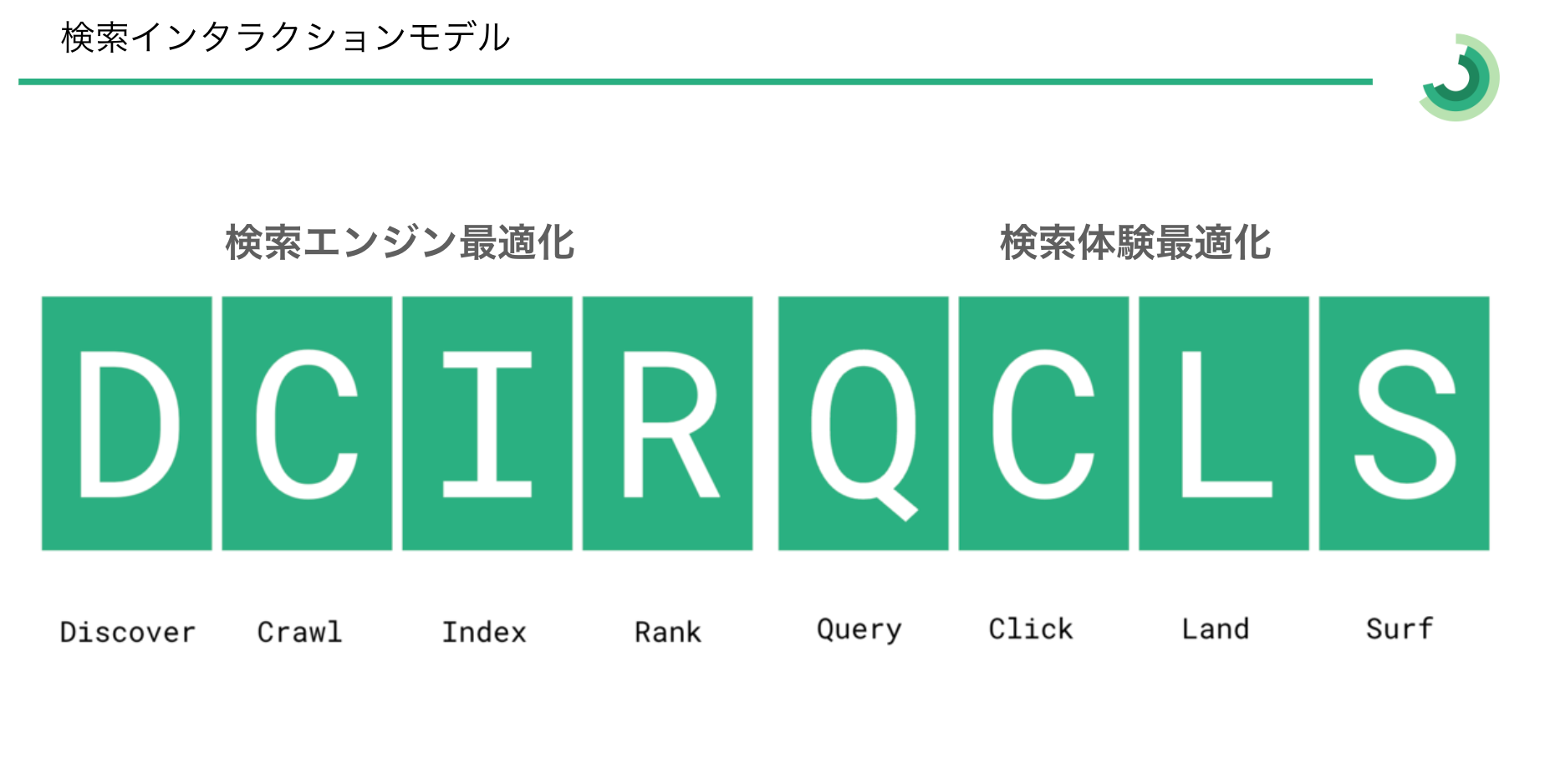
JADE uses a model that breaks the relevant part of the process into three phases: Discover, Crawl, and Index.
DCI: Discover, Crawl, Index

- Discover: The page is found for the first time, for example through a sitemap or an external link.
- Crawl: The crawler visits the page and retrieves its contents.
- Index: The retrieved information is accepted into the search engine’s database.
Thinking in these phases makes it easier to connect each operational problem to a concrete cause and response.
Typical causes and responses by phase
Discover phase
New domains are not discovered quickly
- Cause: Newly launched sites may not yet be recognized by search engines.
- Response: Register the property in Search Console, submit and update sitemaps regularly, and make sure new pages can be requested directly when needed.
Backlinks are too weak
- Cause: Without enough external references, crawlers are slower to find new pages.
- Response: Increase credible backlinks through content promotion, partnerships, social channels, and industry activity.
Crawl phase

Slow page loading
- Cause: Slow pages can reduce crawl efficiency.
- Response: Improve server response time, reduce unnecessary redirects, compress heavy assets, and use CDN delivery where appropriate.
Overly complex site structure
- Cause: If the site structure and internal links are too complex, crawlers cannot move through the site efficiently.
- Response: Simplify navigation, strengthen internal links to important pages, and make relationships between pages clearer.
Incorrect robots.txt settings
- Cause: A misconfigured robots file can unintentionally block important pages.
- Response: Audit the rules regularly and make sure crawl-allowed and crawl-blocked areas are clearly separated.
Index phase
Meta tags are misused
- Cause: Incorrect
noindexor canonical settings can prevent indexing. - Response: Review metadata page by page and correct any settings that block the intended behavior.
Content is low quality or duplicated
- Cause: Thin, overlapping, or insufficiently differentiated content is often excluded from indexing.
- Response: Improve originality, consolidate duplicates, and strengthen topical quality.
Similar content is already seen as low quality
- Cause: If related pages have already been assessed poorly, new similar pages may be deprioritized.
- Response: Rework the surrounding content set to improve differentiation and quality at the cluster level.
Search guidelines are violated
- Cause: Pages that violate search engine guidelines can be excluded or penalized.
- Response: Audit the site against the latest guidelines and correct risky patterns immediately.
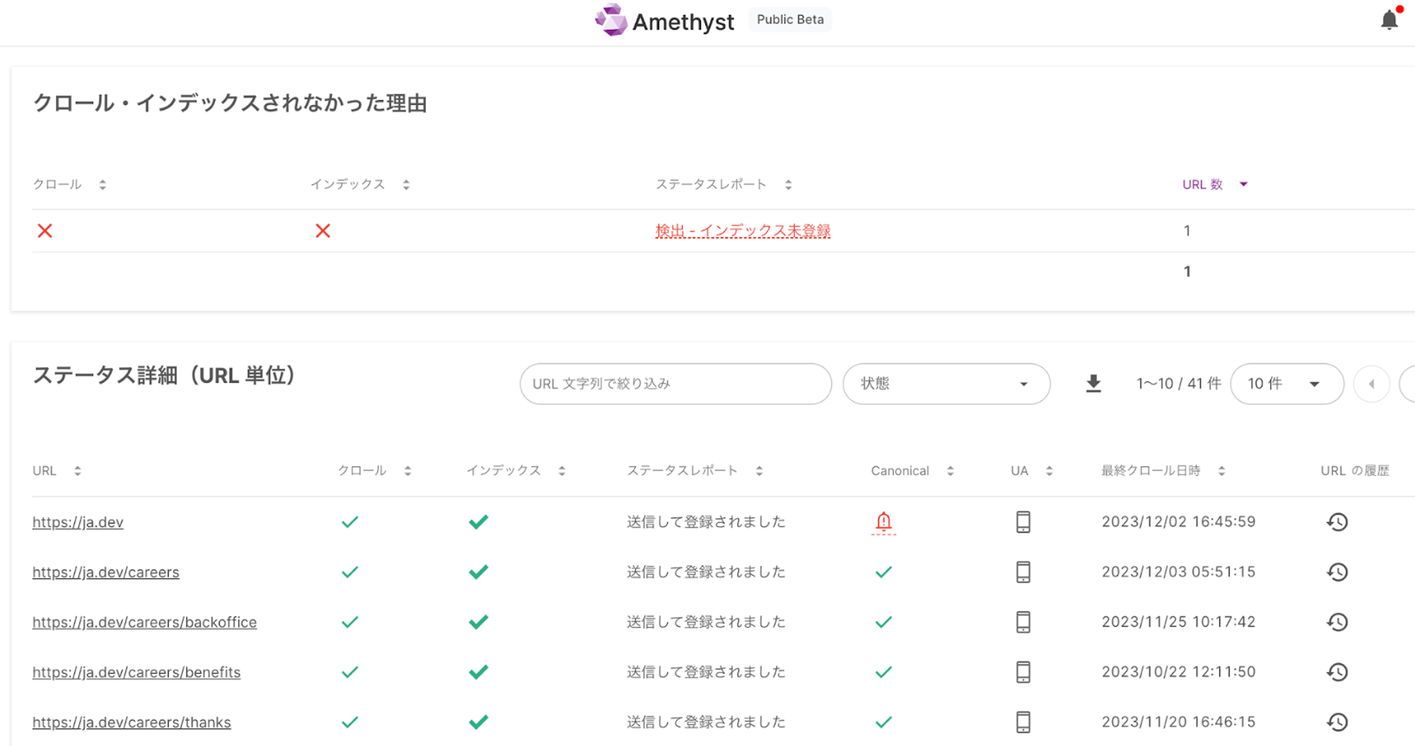
A tool for visualizing crawl and index issues
To improve performance across the Crawl and Index phases, teams need a way to inspect status, reasons, and patterns across many URLs. That is where Amethyst’s Index Worker becomes useful.
Comparison with Search Console
Search Console provides the basics, but Index Worker adds:
- Detailed crawl-rate and index-rate analysis across large URL sets
- Filtering by URL string
- Historical state tracking for individual URLs
- Analysis based on XML sitemaps, RSS feeds, or specific URL groups
- Scheduled recurring inspections
Detailed crawl and index reporting
Index Worker runs URL inspections automatically and produces reports showing crawl coverage and index rate for the targeted pages.

Identifying pages that were not crawled or indexed
It helps teams distinguish between pages that were not crawled at all and pages that were crawled but still not indexed.
Summary
Indexing problems become easier to solve when you separate them into Discover, Crawl, and Index phases. Amethyst’s Index Worker gives SEO teams concrete data for that analysis, which makes it easier to identify root causes and keep improving large sites over time.
Contact us
If you would like a more detailed explanation or documents about Amethyst, please contact us using the form below. A member of our team will follow up based on your message.